 a journal of interesting technical ideas . . . a journal of interesting technical ideas . . .
a journal of interesting technical ideas . . . a journal of interesting technical ideas . . .
Czkawka is a “simple, fast, and free app to remove unnecessary files”. I heard it mentioned on one of the Jupiter Broadcasting shows and decided to look into it.

I have a server that I map folders to using NFS or SFTP that has a lot of accumulated junk. I’ve got twenty plus years of kids pictures, and as the computer expert in the family I’m expected to protect these like crown jewels. However, backing up pictures all the time leads to a lot of duplicates. I also keep all my the family files there - school, work, personal, hobbies - and there ends up being a lot of duplication there as well. Not only are duplicate files a problem for local storage, but I pay to back (not much) it all up to Backblaze B2. Czkawka would be a big help if it helped me sort all those files and conserve space.
Czkawka is available as an AppImage file from Github. I’m using version 3.2 to test.
AppImages are a way of distributing Linux applications can run on any distro - they include all the dependencies so it’s as easy as download and run. They are similar to snaps or flatpaks. They can run from anywhere, so I tend to try them out in my Download directory and then organize them in an “~/Apps” directory if I decide to keep them.
After downloading, you may need to make the file executable.
chmod +x linux_czkawka_gui.AppImage
Once the program starts, there are four buttons across the top to focus a Czkawka search. They are “included” and “excluded” directories, “excluded items”, and “allowed extensions”. The first three are obvious, the last is used to limit searches by type (ZIP files, for instance). Once a set of directories and files is described, the “search” button in the lower left starts the process.
I started by adding the ~/Downloads directory and searching for duplicates. This turned up a few examples of duplicates which it helpfully grouped. Using the program was a bit non-intuitive - you can’t just click on a file and delete it. Instead, you use the select button at the bottom of the window and have a variety of options to select the oldest, newest, or custom. Czkawka doesn’t really let you interact at the file level but at the summary level and the idea is that you’d select all the dups to be deleted in a big set based on some criteria like age. Custom let’s you select duplicates by file path or a pattern in the name. Once you’ve selected a set you can choose the Delete button to remove them.
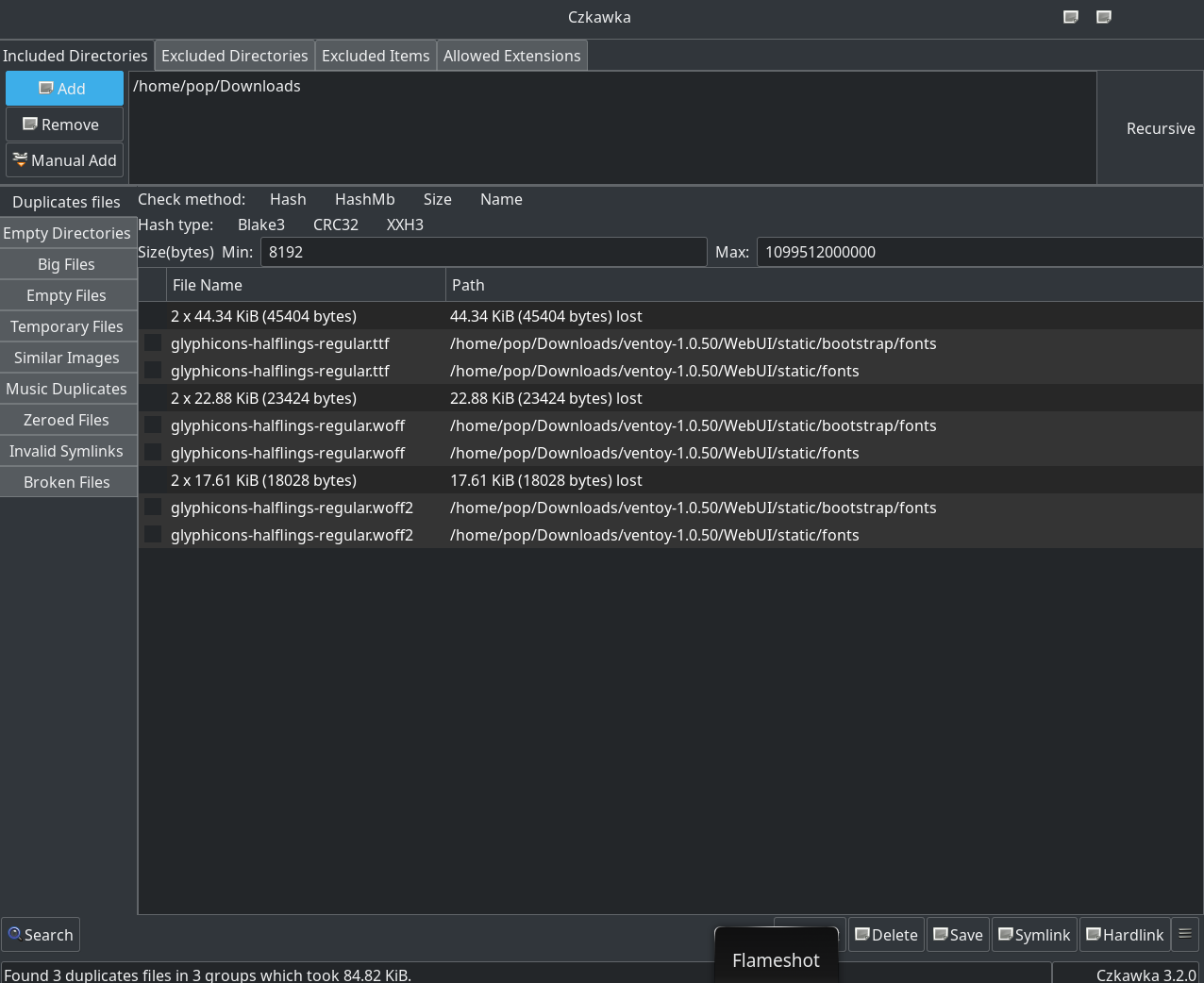
Since I’m not sure about deleting a whole bunch of files, I used “select one oldest” to pick individual files for deletion. This was tedious, but at least the process was under my control. It would have been nice to use the check box on the side to pick the ones I wanted to delete, but the interface isn’t oriented that way. Czkawka does organize the list by size, so you can start at the top to maximize the time spent on freeing up space.
Czkawka does more than just find duplicate files. It will also search for a variety of errors.
Empty directories is pretty obvious, but I was surprised how many orphaned folder’s I’d left moving things around. This process was simple, I selected all, and it remove them. It will also search for Empty Files (zero bytes), which again surprised me by finding examples. Zeroed Files (those filled with zeros) didn’t turn up anything in my test set.
Invalid Symlink will catch things where the referenced file isn’t present. Because I mount remote file systems, I decided not to pursue this for fear it was giving false positives (maybe the mapping was just down). Broken files are those that show corruption. This found a number of files in my Download directory. This could be flagging corruption or an unsupported format. Because of the number of hits and the nature of what was being called out, I decided to defer removing these to look into further.
It will look for big files. My current use case didn’t include this, but I verified it worked. This could be very useful in some administrative situations where a database or a log file has eaten available free space. I might run this occasionally just to identify any runaway inflation (or the things that are causing it).
Temporary Files looks for a variety of extensions including: #, thumbs.db, *.bak, *.temp, *.ds_store, *.crdownload, *.download, *.part, *.cache, *.dmp, and *.partial.
The most fascinating option was to look for similar images. This option uses a perceptual hash to look for images that may differ in resolution or cropping. This worked really well. I found cases where we had saved cropped images and was able to delete the extra versions. Music Duplicates uses tags to perform a similar analysis. Here I would have appreciated details, such as the different encoding used.
Czkawka is billed as fast. My testing mostly backed this up. On a local disk, searches ran seconds. It took longer to process a directory over SFTP, for instance, although this would be expected.
I developed a couple ideas about how to best handle these situations. First, I suggest installing the application on the file server and running it locally. My file server is headless, but Czkawka has a command line version for just such situations. Second, try reducing the size of the search field. Use subdirectory to limit it, for instance. Third, I suggest running some of the quicker scans (like “empty files”) first to reduce the size of the dataset.
At one point I was searching through a hundred thousand remote files. As you might expect, the search took a few minutes.
I liked it and plan to keep using it.
Any time I look at a Linux program, I remember that it is being developed and freely offered to the community. The people behind these projects need to be celebrated and appreciated. That said, not everything on GitHub is “fully baked”.
I’m pleased to report that Czkawka is a well thought out and reasonably fast program that does what I expected - it helps me “weed the garden” on my file server and remove the detritus. I’m not crazy about the file selection process and I recommend that you bring up a file manager to compare with the Czkawka searches to make sure you understand what it is finding. Anytime you are dealing with a mass deletion program you want to be extra careful! But the results made sense to me. I didn’t delete everything it nominated, but I was able to save a lot of space in the end.