 a journal of interesting technical ideas . . . a journal of interesting technical ideas . . .
a journal of interesting technical ideas . . . a journal of interesting technical ideas . . .
Most of my writing is in markdown in two applications - Visual Studio Code (where I write blog posts amoung other things) and Obsidian. Although initially reluctant, I’ve grown to appreciate the portability and easy reuse that markdown allows. The problem is that the rest of the world doesn’t always appreciate what is obvious to me. As an example, the folks at work prefer their documents in Office formats.
One of the things I love about markdown is that it’s an easy format to migrate to and from, perhaps because it’s a simple format. I wrote about an automated process to take Word documents, convert them to markdown, and incorporate them into your Obsidian vault in Word to Obsidian with a DIY CI.
 The techniques I used in the above article could be used for any type of file format changes, but exporting from Obsidian isn’t always to DOCX and isn’t always aimed at a particular directory. In fact, if you are using O365 then it may need to be uploaded to an arbitrary place on OneDrive/Sharepoint in a seperate step. Instead, I’ve found the best method to be the Pandoc Plugin.
The techniques I used in the above article could be used for any type of file format changes, but exporting from Obsidian isn’t always to DOCX and isn’t always aimed at a particular directory. In fact, if you are using O365 then it may need to be uploaded to an arbitrary place on OneDrive/Sharepoint in a seperate step. Instead, I’ve found the best method to be the Pandoc Plugin.
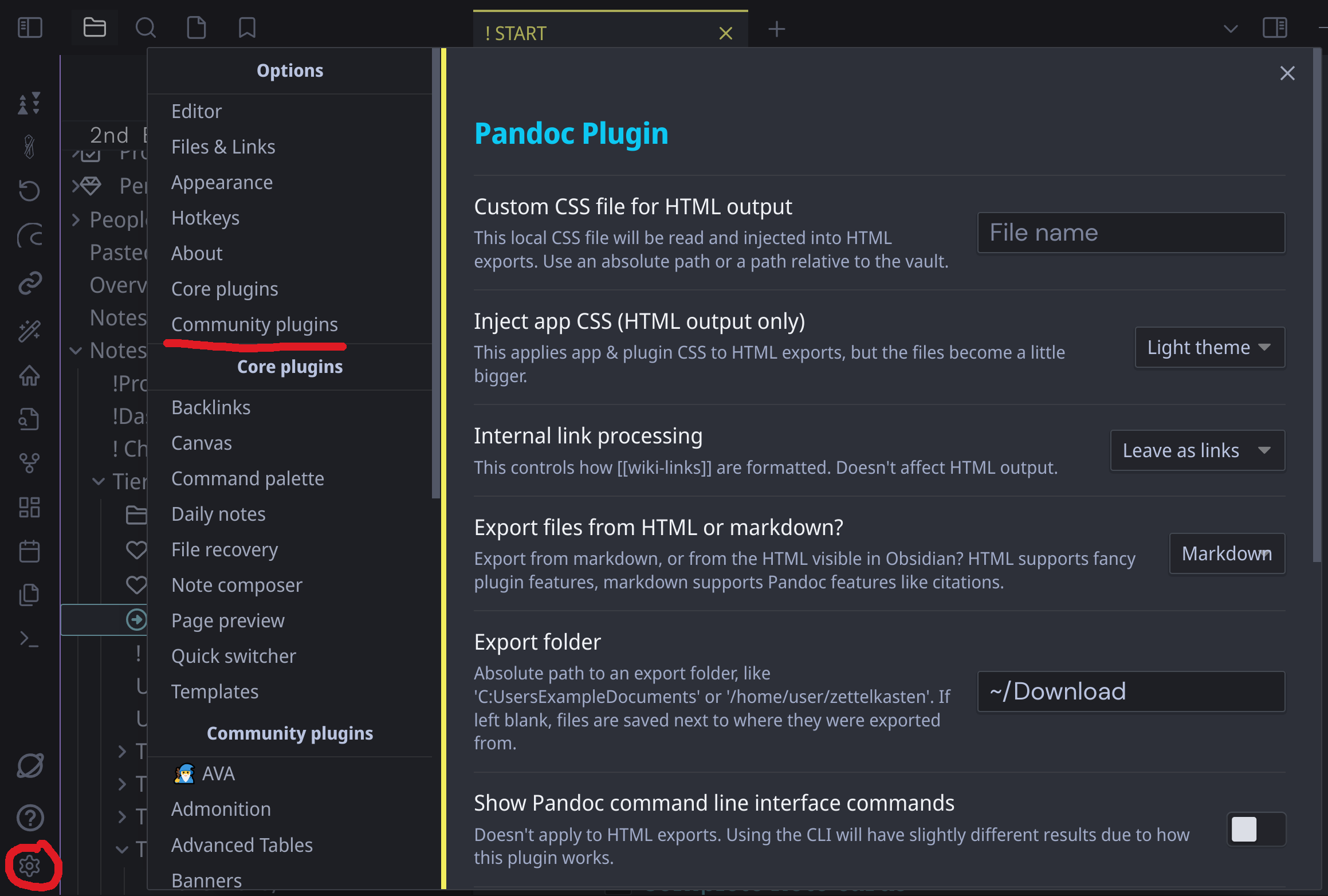
In Obsidian, go to options (the cog in the lower right), then to _Community Plugins" and search for Pandoc. This presents an “install” button, which adds the plugin to your vault and it can then be enabled. Don’t forget to enable it! I do that sometimes and then wonder why it’s not working.
I’ve found that the plugin exposes Pandoc options pretty well and that default settings work well (I’ve mostly used it to export to DOCX and PDF). There are options to supply default formating to the document, but they’re not necessary.
Other sources of markdown files, such as those from Hugo or Github, can be converted using Pandoc on the commandline. The issue here is that Hugo files typically include embedded images, and the images are specified based on where the image ends up after compilation. When you run hugo it takes the markdown directories and produces a set of html files in a new structure. On this blog, my images are refrenced at the “root” pre-compilation, for instance “/image.png”, alongside the written content. In the on-disk structure (and you can see this in the github) my writing is under “/post/file.md” and the images are under “/static/image.png”.
When Pandoc runs against the raw Hugo markdown, it just references the path and produces compilation errors. I also use CSS to style images, which modifies the URL (for instance “/image.png#floatright”). The CSS markings are also lost on Pandoc and will cause errors. There are three ways to deal with this. The first is to manually edit the markdown to remove the image or correct the path. Options two and three involve a pre-processor, a piece of lua code that Pandoc runs mid-conversion. Option two is to use a lua pre-processor to remove all images.
brent@hyper > cat filterimagesinpandoc.lua
function Image () return {} end
Option three is to use a lua pre-processor to correct the path and remove the styling. No code demonstrated here because I use option 2 and the code would depend on your directory structure.
The final trick to converting markdown - Hugo, Obsidian, or any other - is to understand that Pandoc expects markdown to begin with a YAML header. That header can be as simple as an authors name. The YAML ends with a line of three dashses.
author: Brent
---
Pandoc will fail if it doesn’t see that YAML header. Most Hugo files and most Obsidian files are going to include that header, so you should be okay. Pandoc also gets confused if it sees three dashes on a line later in the file. I used that to generate a seperator line in Obsidian and caused Pandoc to blow up. Make sure that there is at least a primitive YAML header AND that there’s only one line of three dashes.
Converting ends up looking like this. This command specifies the source (markdown.doc), the output file and format (Word.docx) and the filter.
pandoc ~/Folder/markdown.md -o Word.docx --lua-filter filterimagesinpandoc.lua
So rock on with Markdown and convert to Word as you need to live with the normies. Hope this helps!